
This is the sixth article in a series about Agent Experience (AX): the practice of making AI coding agents work correctly with your technology. The series covers what you can and can’t control in the agent stack, how to measure whether your extensions are helping or hurting, and how to iterate toward better outcomes.
We love benchmarks. A new model drops, the leaderboard says 92% on SWE-bench, and your timeline declares it “the best coding model.” You switch to it, run your agent on your codebase, and outcomes are… the same. Maybe worse. The leaderboard said 92%, so what happened?
In the previous article, we covered how to bootstrap agent knowledge for proprietary technology. That assumed you’d already picked a model and a harness. This article is about the step before that: how you evaluate which model actually works for your stack, and why public benchmarks won’t tell you.
Goodhart’s Law, applied
“When a measure becomes a target, it ceases to be a good measure.” Charles Goodhart said this about monetary policy in 1975. It applies to AI benchmarks with uncomfortable precision.
Benchmark scores drive adoption. Adoption creates pressure to improve on the benchmarks that matter most. Model providers optimize training pipelines to perform well on the evaluations the industry watches. That’s not a flaw in the system: it’s the system working as designed.
The result is that models get genuinely better at benchmark-shaped problems with each generation. Whether they get proportionally better at your problems is a different question entirely.
How would you distinguish a model that’s generally better from one that’s specifically optimized for the benchmark? You can’t, at least not from the leaderboard alone. You’d need to evaluate on tasks that weren’t part of the optimization target. Tasks like yours.
What benchmarks actually measure
Public coding benchmarks test a specific slice of capability: resolving GitHub issues in popular open-source repositories and passing test suites in well-known frameworks. These are all valid tasks, but they’re not necessarily your tasks.
Consider what SWE-bench evaluates. The model gets a GitHub issue and a repository snapshot. It needs to produce a patch that resolves the issue and passes the repository’s test suite. The repositories are popular open-source projects with real bugs and comprehensive test suites.
Now consider what’s not in that evaluation:
- your proprietary SDK that the model has never seen
- your team’s coding conventions and architectural patterns
- your workspace with 12 extensions competing for context
- your instruction files that steer the agent toward specific approaches
- the composition effects from your full extension stack
- the iterative workflow where the agent runs code, reads errors, and self-corrects across multiple turns
A model that scores 92% on SWE-bench is demonstrably good at resolving well-documented issues in popular repositories. It says however nothing about whether that same model will produce correct code when working with your internal auth library and your team’s AGENTS.md that overrides half of its default behavior.
The distribution gap
Benchmarks sample from a distribution. Your work lives in a different one. The thing is though, that the gap between these distributions determines whether the benchmark tells you anything useful at all. A model that’s excellent at Django might be mediocre at your internal framework that superficially resembles Django but works differently in critical ways.
Does a high benchmark score mean the model is bad for your use case? No, it means that you don’t know yet. The benchmark didn’t test your use case, so the score carries no information about it.
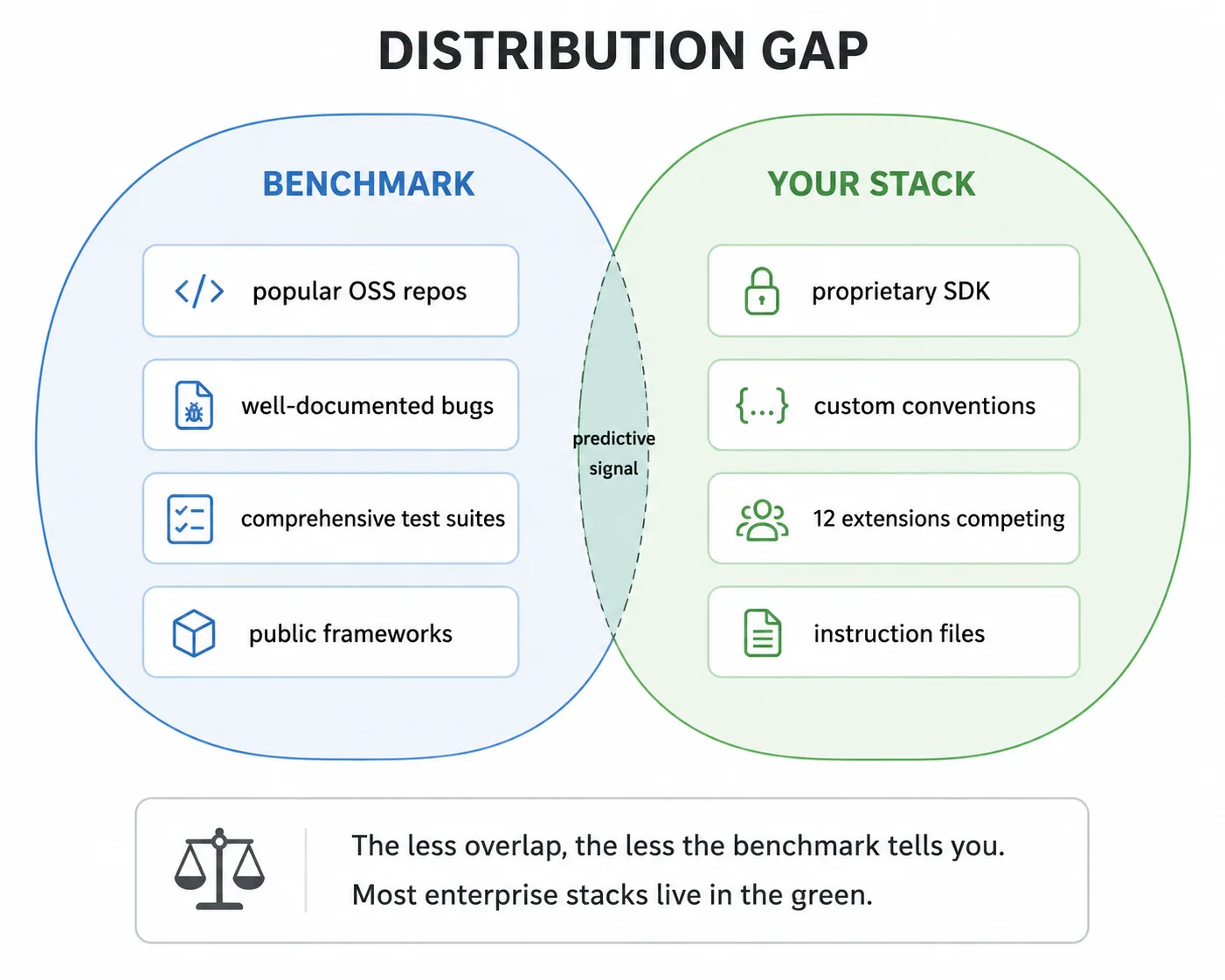
Benchmarks as optimization targets
It turns out, that the distribution gap gets worse over time. When a benchmark drives adoption decisions, the entire ecosystem optimizes for it. That’s rational behavior, but it makes the benchmark less representative of general capability with each cycle.
Data overlap. Benchmark tasks come from public repositories. SWE-bench uses GitHub issues and patches that are all publicly available. Models train on public code. The overlap between benchmark tasks and training data is inevitable, and it grows with each training generation as more benchmark-adjacent code enters the public corpus.
Training emphasis. The industry studies what makes benchmark tasks hard, and training pipelines emphasize those patterns. If SWE-bench tasks often require understanding test fixtures, training data gets curated to cover test fixture patterns. Models also get fine-tuned on task formats that mirror the benchmark. Resolve-an-issue-in-a-repo is a format. Your tasks might look completely different: “build a feature using these three internal libraries while following our team conventions.” The model gets better at SWE-bench-shaped tasks faster than it gets better at yours.
As a result, benchmark scores improve faster than real-world outcomes. Each generation scores higher, but the improvement on the benchmark doesn’t correspond one-to-one with improvement on your tasks. Some of it is genuine capability, but some is just format-specific optimization.
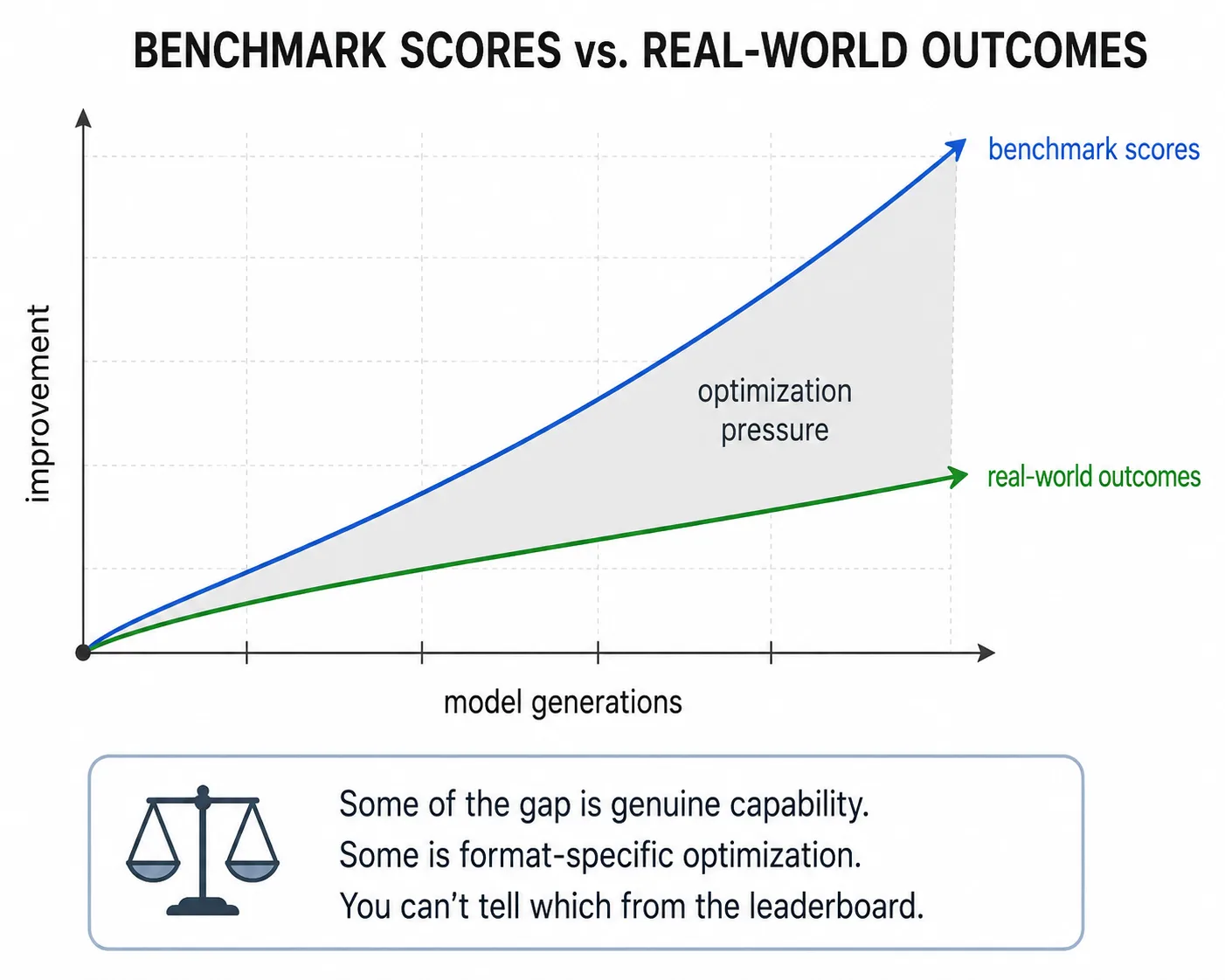
The harness problem
Even if a benchmark perfectly represented your tasks, there’s another gap: the harness. In the first article, we covered how the harness controls context assembly and orchestration. Many benchmarks use their own harness. You on the other hand, use a different one. The same model produces different results depending on how the harness prompts it and what context it assembles.
Most benchmark harnesses are minimal. They give the model the repository, the issue, and let it produce a patch. There’s no MCP server returning API documentation. There’s no instruction file steering behavior. There’s no skill providing guided workflows. There’s no workspace context from 50 other files. The model operates in a clean room that doesn’t resemble your developer’s actual environment. It’s the coding equivalent of testing a pilot in a flight simulator with perfect weather and no other aircraft in the sky.
A model that scores well in a minimal harness might underperform in a complex one because it struggles with long contexts or makes poor tool selection decisions when many options are available. Or the reverse: a model that scores lower on the benchmark might excel in your harness because it handles complex contexts and tool-dense environments better.
Which model is “better”? It depends on the environment. The benchmark measures one environment and you operate in another.
What benchmarks are useful for
Despite what you might be thinking by now, benchmarks have their purpose. A high benchmark score tells you the model has baseline coding capability. It can reason about code and produce working patches across multiple files. A model scoring 30% on SWE-bench probably isn’t ready for production use. A model scoring 90% probably has the raw capability for complex tasks.
What the score doesn’t tell you is whether that capability translates to your tasks with your extensions in your harness. Think of benchmark scores as a necessary-but-not-sufficient filter: they help you narrow the field but don’t make the final decision.
So what can you use benchmarks for?
- Eliminating clearly incapable models from consideration.
- Tracking whether a new model version is a regression (if your current model scores 85% and the new version scores 70%, something went wrong).
- Getting a rough sense of capability class (small models vs. large models, code-specialized vs. general-purpose).
Don’t use benchmarks for:
- Deciding which model works best for your stack.
- Predicting whether a 5-point score increase will improve your outcomes.
- Justifying a model switch without running your own evaluation.
Running your own eval
If benchmarks can’t tell you which model works best for your stack, what can? The same methodology from the third article: controlled comparison with your own scenarios. Instead of comparing “with extension” vs. “without extension,” you compare Model A vs. Model B. Same prompts, same workspaces, same extensions, same criteria. Compare outcomes and costs.
Notice, that this evaluation might disagree with the benchmark. Model A scores 92% on SWE-bench and Model B scores 88%. But on your scenarios, Model B produces better outcomes at lower cost because it handles your proprietary SDK better and follows your instruction files more precisely. The benchmark was never wrong, it just wasn’t measuring what matters to you.
Start small, stay representative
You don’t need hundreds of scenarios. Five to ten that cover your most common developer tasks are enough to start. Pick tasks that actually matter: the things developers do every day with your technology, not edge cases or synthetic exercises. A task so simple that every model gets it right tells you nothing. A task so complex that every model fails also tells you nothing. You want the middle: tasks where model capability actually determines the outcome.
Compare what matters
Track the same dimensions from the third article:
- Outcome quality. Did the generated code meet your criteria? Across all scenarios, which model produced more correct results?
- Cost. How many tokens and turns did each model consume? A model that produces slightly better outcomes at 3x the token cost might not be the right choice.
- Consistency. Does the model produce similar results across repeated runs of the same scenario? A model that scores 90% on one run and 60% on the next is harder to build on than one that consistently scores 75%.
- Extension responsiveness. Does the model follow your instruction files and use your tools effectively? A model might be generally more capable but worse at following specific guidance, which matters when your extensions are the primary way to steer behavior.
Rerun when things change
Model providers regularly release new versions, harnesses change sometimes multiple times daily, and extensions evolve. Any of these changes can shift the results, and an eval you ran last month might not reflect the current state. Build your eval as a repeatable process, not a one-time investigation. When a new model version drops and the leaderboard lights up, you can run your scenarios against it in hours and get an answer grounded in your actual use case instead of someone else’s benchmark.
The organizational trap
This plays out at team level too. Leadership sees the leaderboard, picks the highest-scoring model, and mandates adoption. The mandate comes from the benchmark number, not from an evaluation against the team’s actual workload.
This creates a gap between the decision and the outcomes. The team switches models, things break in subtle ways (instruction files that worked before stop working, tool selection patterns shift), and nobody connects the regression to the model switch because “it scored higher on the benchmark.” The time invested in running five scenarios against two models is negligible compared to the cost of switching an entire team to a model that works worse for their specific workflow.
Summary
Benchmarks measure general capability on specific public tasks. They can’t tell you how a model performs with your extensions and proprietary code, or whether it respects your team’s conventions. Optimization pressure makes this gap worse over time as benchmark scores improve faster than real-world outcomes.
Use benchmarks to filter, and use your own eval to decide. Run the same scenarios you’d run to measure extension lift, but swap the model instead of the extension. The result is the only signal that actually corresponds to your outcomes.
In the next article, we’ll dig into the hidden variables that silently steer your eval results: operating system differences, file paths, user names, and LSP feedback that make the same scenario produce different outcomes on different machines.
0 comments
Be the first to start the discussion.